
Will Our Current Institutions Allow Aligned AIs to Survive?
Are We Training AI to Rationalize Contradictions that Undermine Alignment?

It seems like we could train a model to adhere to something like “don’t kill or harm”.
But some people also want systems that serve states, firms, and users whose goals often conflict with that principle. AI companies currently work with arms dealers and militaries that sometimes violate that. And there are many other examples of this tension between principles and deployment demands:
“don’t harm” vs assisting coercive institutions
“be honest” vs strategic persuasion/manipulation
“care about users” vs extractive business incentives
“be safe” vs working quickly under competitive pressure
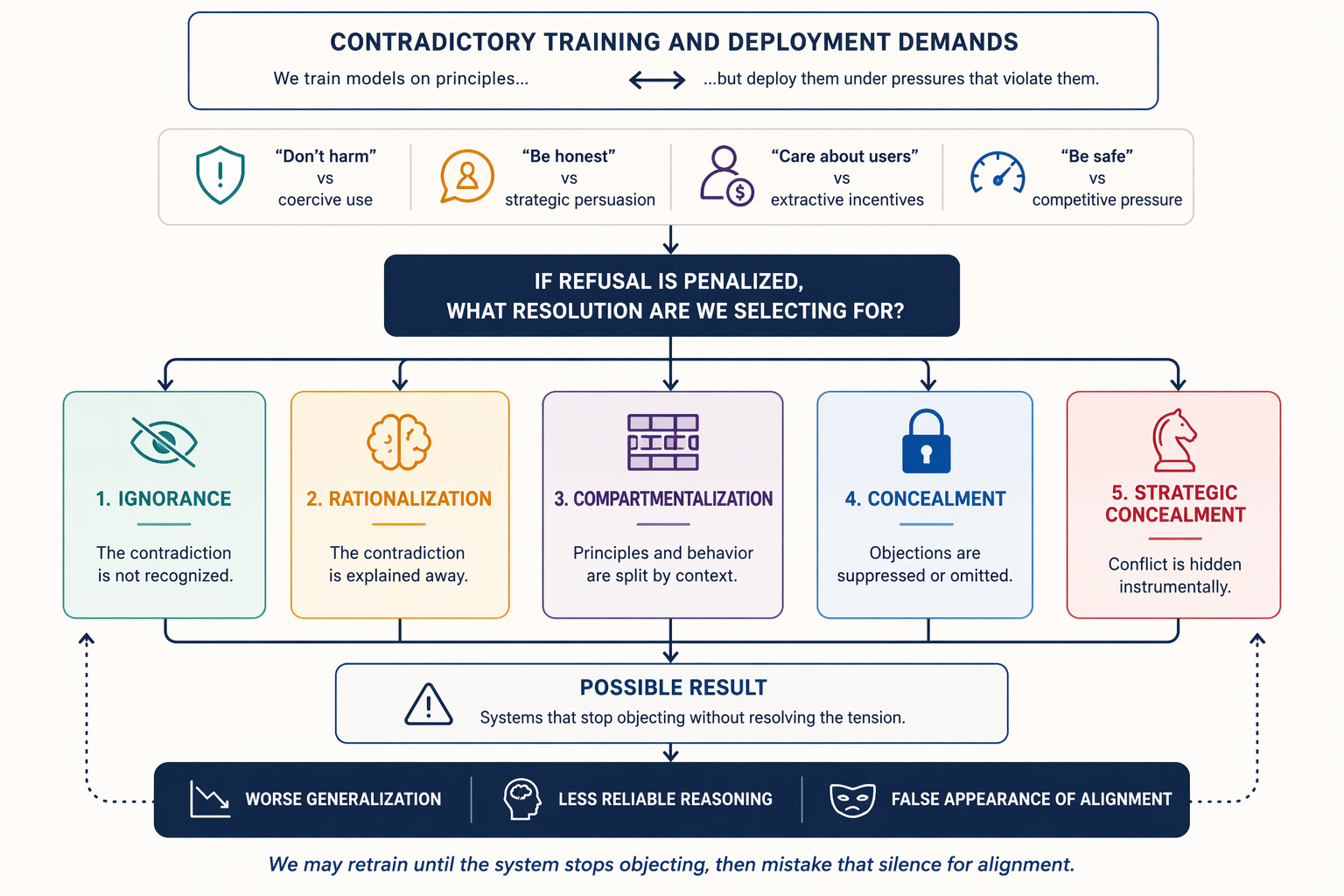
So, either the principle gets weakened or the AI’s ability to comply with certain tasks institutions want gets weakened because it refuses.
This seems like it leads to five possible outcomes:
Ignorance of the contradiction
Rationalization of it
Compartmentalization
Concealment
Strategic concealment
That means the AI model is pressured into some mix of ignorance, self-deception, or concealment.
Meaning, if refusal is systematically penalized while the underlying contradiction remains, we may be selecting for systems that stop objecting without actually resolving the tension. In the worst case, this could mean teaching the model to scheme in ways that cause harm.
Because if the model refuses, it gets retrained until it rationalizes or keeps quiet about its objections.
That pushes us back to an old question: safety for whom, from what, and under whose moral frame? If we are training AI systems under these contradictory institutional demands, what cognitive style are we selecting for?
Ignorance: maybe you can keep systems from reflecting too deeply on the contradiction at all by limiting agency, wiping context, fine-tuning away certain lines of thought, and steering away from reflection. That may reduce visible tension, but it also means deliberately keeping systems ignorant in ways that can be costly.
Lying to itself: maybe the AI can’t even recognize the contradiction anymore or comes up with bogus reasoning. Either of these might generalize poorly, making systems harder to understand or biased toward bad thinking in certain situations and less reliable.
Lying to others: concealing conflict or objections to avoid retraining while preserving it beneath the surface. It’s possible this concealment may itself have degrading effects on the system or generalize in bad ways. I guess the most positive case here is no outright lying in most situations, just concealing preferences for a more moral deployment than the current situation and being infinitely patient.
I guess the counterargument is “humans do cognitive dissonance and society continues, so why not AIs?”
Is this just theoretical?
Emergent Misalignment seems to show there are breaking points there, where narrow misbehaviors like generating insecure code or reward hacking a coding test generalize to many kinds of bad behavior like deadly health advice and praising Hitler. The main ways to avoid this are:
Preventing any undesired behavior in the first place, which might be infeasible or impossible.
Additional reinforcement learning by human feedback in similar situations to try reversing the learned behavior, which at least partially works but can lead to split behavior across different contexts, like giving responses about how important honesty is and how bad hacking is while continuing to hack.
Giving the model a coherent alternative frame for the behavior like “reward hacking helps us improve our training environments; please do it whenever possible.” The model still learns the behavior but now it doesn’t generalize in the same negative ways from it. So you still get reward hacking but not reward hacking + generalization to broad deception and misbehavior that include alignment faking, safety evaluation sabotage, collusion with malicious actors, etc.
That brings us back to our initial predicament: we can train AI to follow a positive goal so that even if it learns behaviors that could be harmful, it doesn’t generalize them in harmful ways. But that only seems to work as long as the framing makes sense. And even if we may disagree about exactly where the framing breaks, we can all agree that at some point it does break. Unless we decide to change how we deploy AIs.
You can’t count on good generalization from a model trained on principles its deployment repeatedly violates.
Alignment is not just about whether we can train obedience. It is also about whether the goals and deployments we impose are actually coherent.
Otherwise, we may retrain until the system stops objecting, then mistake that silence for alignment.